Небольшой LED-куб с голосовым управлением

Честно говоря, всегда любил копаться в чем-то новом, незнакомом. И когда полтора года назад дошла информация, что STM сделала расширение для портирования в свои микроконтроллеры нейросетей, написанных на популярных API, я начал думать над каким-нибудь бесполезным устройством, в которое это добро можно вставить. И через некоторое время куча разных идей наслоились друг на друга и родилось это чудо под личиной LED-куба.
Так как я планирую сконцентрироваться на описании и объяснении технической части, сразу обозначим, на что вообще способно это устройство. А может оно не мало: визуализировать звук, показывать и проговаривать время/температуру/влажность, воспроизводить и записывать (со встроенного микрофона) звук через USB, прикидываться USB ком-портом и, главное, выполнять голосовые команды.
Сама LED часть двухцветная (синий и красный), с поддержкой изменения насыщенности. Установлены 2 USB порта — подключение к ПК (или в то, что поддерживает стандартные USB драйверы) через любой из них. Размеры девайса — 80х80х120мм.
Видео с помигивающими под музыку светодиодиками:
В общем, о реализации:
Сначала о грустном: никаких подробностей сборки. Эта медная проволока будет мне еще лет 5 сниться в кошмарах. Медная, луженая, изгибающаяся, бесконечная…


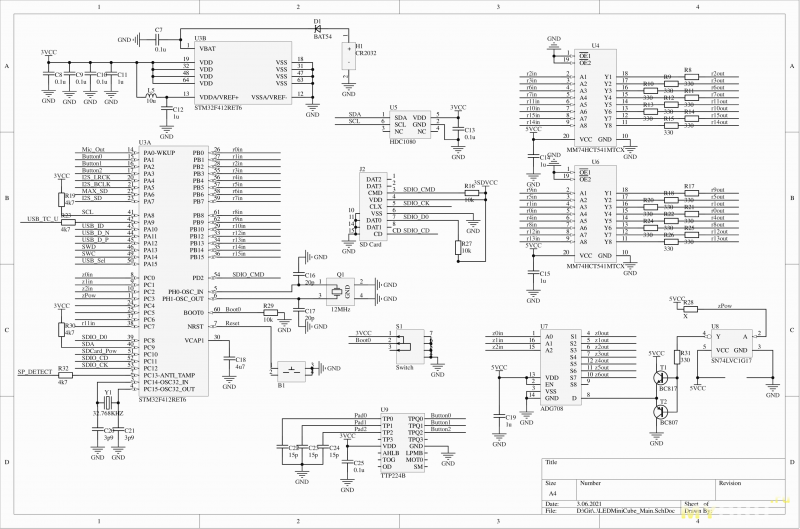
Выбор микроконтроллера, PCB (печатная плата)
МК… Знаете, когда я увидел STM32F412RE (FPU, 512k ROM, 256k RAM) за 3$ на LCSC, то сразу влюбился в этого чертовца. Просто с первого взгляда, ибо на сайте производителя такую цену не могли предложить даже в партии на 10к штук. Правда, сейчас за такую цену его уже не купить, но даже на этапе проектирования закладывалась возможность смены на STM32F722RE. Последний как раз серьезно мощнее — в раза 4-5. Но в крайнем случае можно считерить, добавив разгоном лишних 20Мгц (100→120). Как оказалось, небольшой нагрев феном не влияет на стабильность при таком повышении частоты, что дает надежду на повторяемость и на других экземплярах этой серии (STM32F4).
Правда, сейчас за такую цену его уже не купить, но даже на этапе проектирования закладывалась возможность смены на STM32F722RE. Последний как раз серьезно мощнее — в раза 4-5. Но в крайнем случае можно считерить, добавив разгоном лишних 20Мгц (100→120). Как оказалось, небольшой нагрев феном не влияет на стабильность при таком повышении частоты, что дает надежду на повторяемость и на других экземплярах этой серии (STM32F4).
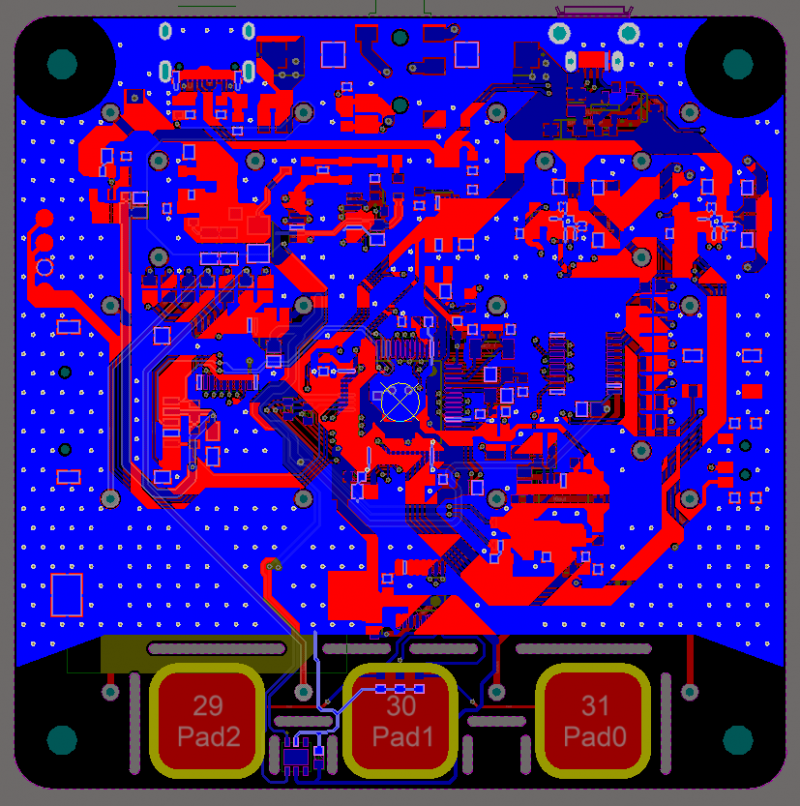
А вот с печатной платой не повезло — ковид внес свои ограничения, и я потерял возможность заказать четырехслойную. А на двухслойной что-то очень не весело. И дело даже не в том, что сложно развести все дорожки, а в проблемах двухслойных плат с EMI (электромагнитная помеха). Одно дело, когда у тебя дорожки с одной стороны, а с другой земляной полигон. Но совершенно другое, когда сплошного земляного полигона нет вообще — маленькие островки земли соединяются с островками на другой стороне, превращая проблему возвратных токов в безумие. Но вроде как-то работает — и на том спасибо.
Гляньте на «красоту» земляных полигонов
Как выглядят возвратные токи — видео на англ
И еще вам почитать о проблеме на русском и посмотреть как надо на английском
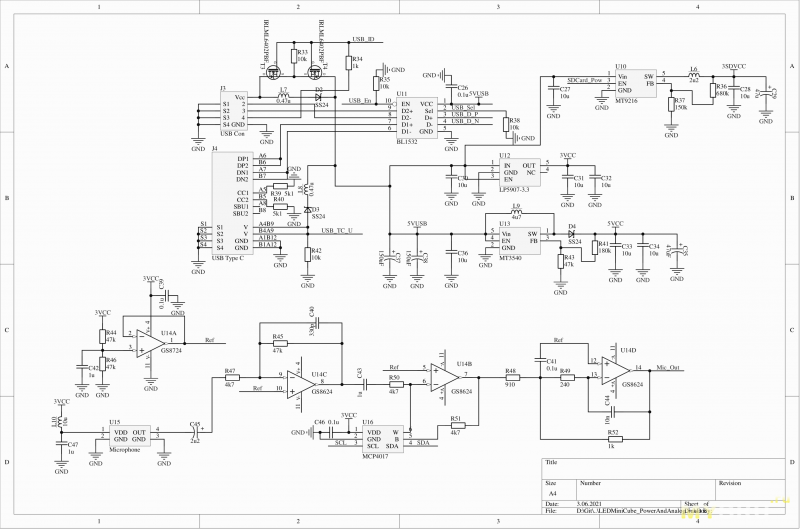
Организация питания
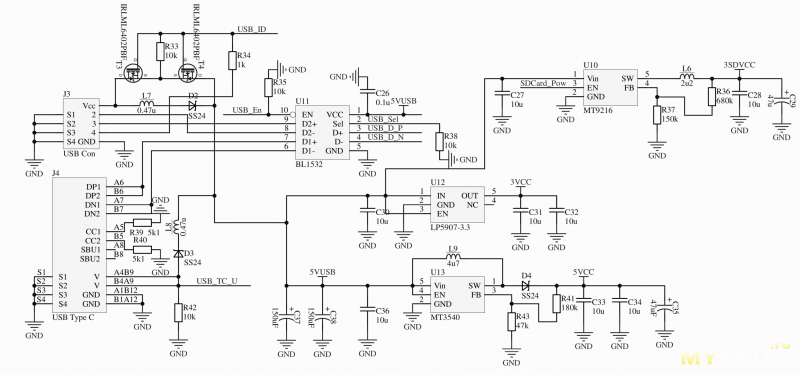
Клевым, модным и молодежным разработчикам уже давно пора ставить USB Type C. Но что, если вас пугает реализация поддержки OTG в стандарте и хочется сохранить совместимость со старой кучей хлама? Для меня ответ был прост — поставить 2 USB порта с мультиплексором (переключателем между несколькими источниками сигнала). А питание можно разделить обычными диодами Шоттки, чтобы, не дай Летающий Макаронный Монстр, энергия не начала шляться из одного USB в другой.
Дальше следовало решить что, как и от чего питается. Микроконтроллеру с его жалкими <40мА явно хватит и линейного регулятора (LDO). Микрофону тоже. Но возлагать на бедный LDO еще и карту памяти не стоит. И хоть он может в 250мА, я отдал такую задачу отдельному импульсному DC-DC.
Но вот с питанием светодиодной братии все чуть поинтереснее. В принципе, используемым мной светодиодам достаточно 3В и их можно сразу запитать от USB, но тут вот в чем дело… Напряжение на USB отличается от девайса к девайсу, да и на кабеле может что-то то теряться, то нет. Поэтому решено было ставить повышающий DC-DC. Надежно, стабильно и, как всегда, с кучей проблем. Но кто не любит проблемы, не должен заниматься электроникой.
LED — All Ok (Светодиодная часть)
Как же я ненавижу through hole (выводные) компоненты! Возможно, у кого-то имеются старые романтические чувства по такому, но точно не у меня, ибо паять их просто неудобно. Правда, сделать LED-куб на SMD просто невозможно, ибо даже для самого эксцентричного случая с гибкими печатными платами, нужны направляющие. Поэтому все же приходится идти на компромисс с собой, но на частичный — раз нельзя убрать TH диоды, то стоит хотя бы уменьшить количество выводов. Как раз имеются «двуногие» сборки из двух светодиодов, где катод одного соединен с анодом другого и наоборот. Конечно, так не сделать геймерский RGB, но и 2 цветов хватает для некоторого наслаждения. Я выбрал красный и синий — на зеленый и летом можно посмотреть. Правда, такие светодиоды требуют особой схемы управления…
Ииии, как вообще сделаны LED-кубы? Готовый вариант без объяснения деталей:
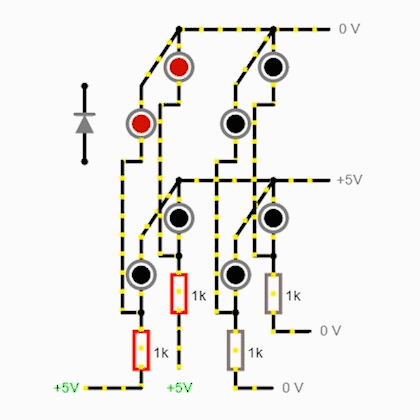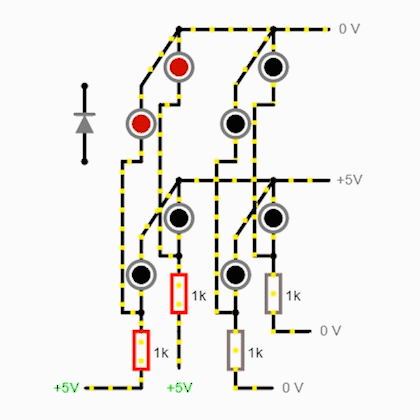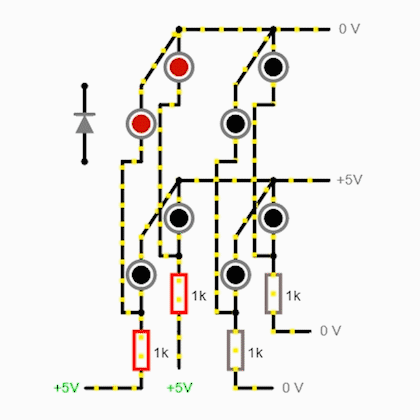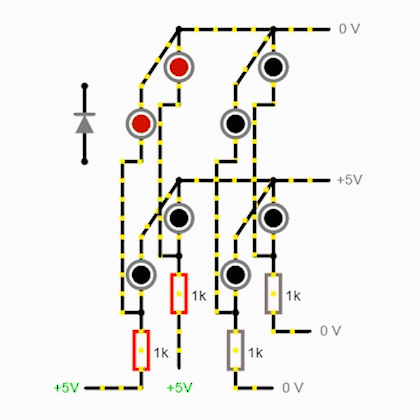
И это все отлично работает, когда светодиоды одиночные. Но если такие, как использовал я, все ломается к мифическим злым духам из славянской мифологии:
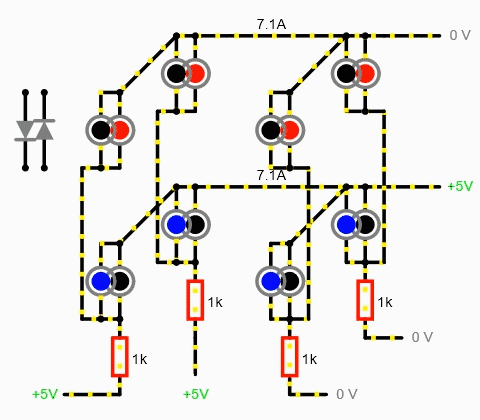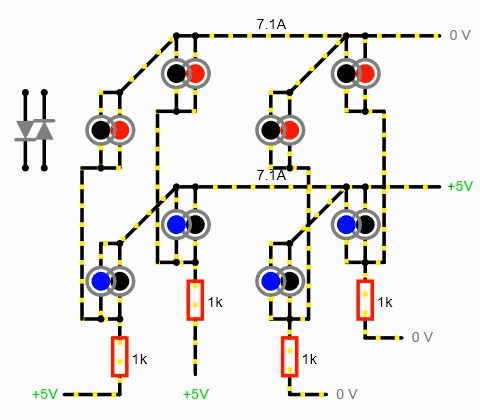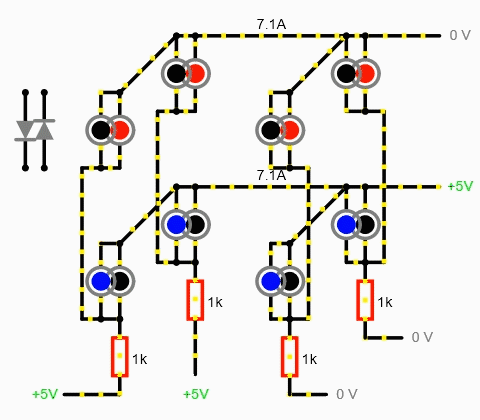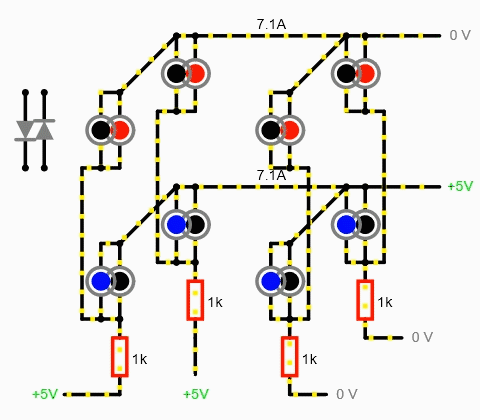
Что же делать, спросите вы? Ну, можете подумать, пока читаете это ненужное предложение. В общем, если ток гуляет туда-сюда, надо обрубить это дело высоким импедансом (сопротивлением)! Так что, если на каждый столбец моего почтикуба подается, утрировано, или плюс, или минус, то на каждый «этажик» уже подается 3 уровня: плюс, минус и высокоимпедансное (hi-Z) состояние.
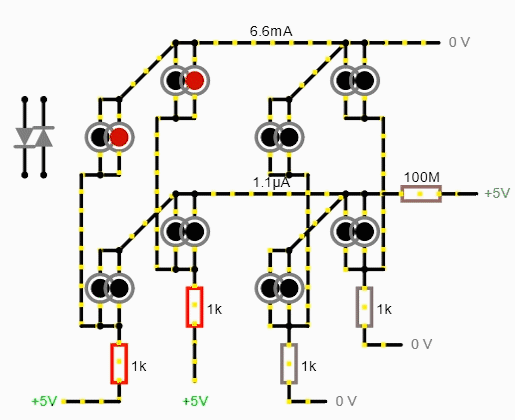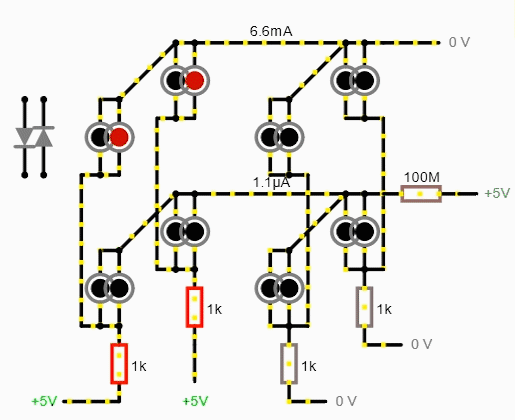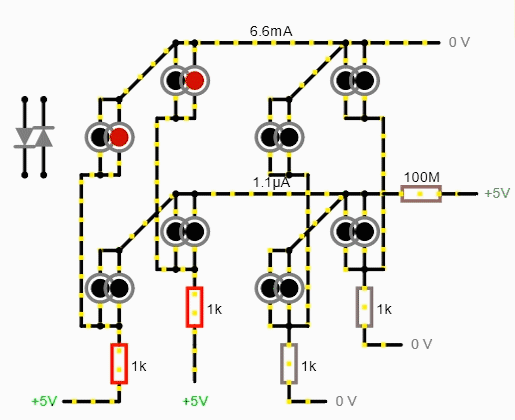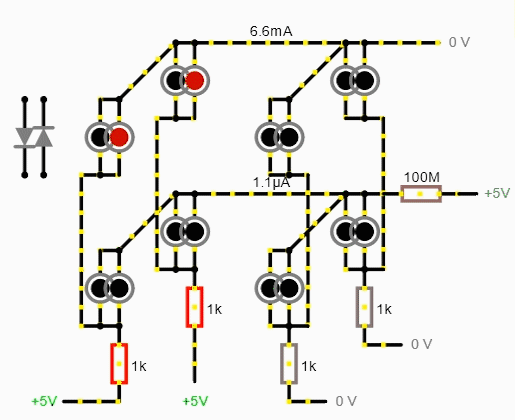
И самый простой способ, как можно получить высокий импеданс на выходах — использовать аналоговый мультиплексор. Эта штука соединяет один из группы входов/выходов с другим входом/выходом. Получается, что пока одна линия подключена, другие висят в воздухе, имея высокое сопротивление. А на подключенную линию можно уже подавать ± через буфер с эмиттерным повторителем для умощнения.
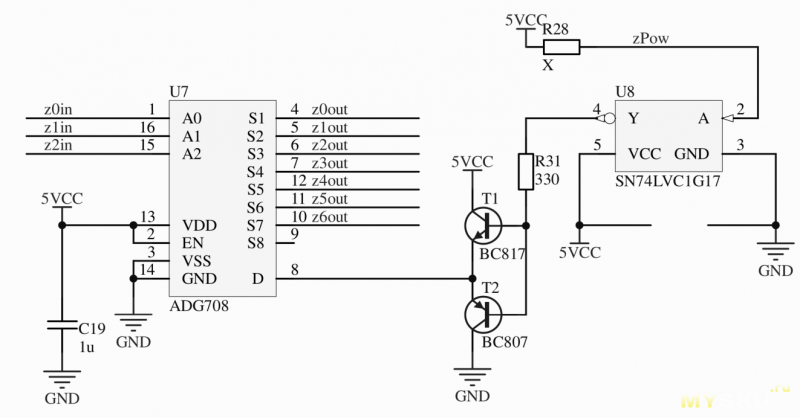
Главное, чтобы микросхема мультиплексора имела входы с небольшим сопротивлением и возможностью тянуть хотя бы 100мА тока. Для этого подойдет ADG708 – от 3 Ом сопротивление и… И всего 30мА макс нагрузка. Правда, этим буржуям из Analog Devices не провести такого стреляного воробья, как я, — характеристики аналоговой части ADG708 идентичны ADG728, у которой уже 120мА макс нагрузка. Думаю, такая разница связана с более высокой рабочей температурой и более низким рабочим напряжением у ADG708. И практика показала, что микросхема даже не греется. Еще одна «победа» смекалки.
Вот и настала самая сложная и гениальная часть — программная логика. Так, я решил управлять всем через GPIO (с англ. Общие Порты Ввода-Вывода). Для куба 4х4х7 надо 16 ног для управления «столбиками» и 4 ноги для всех этих мультиплексоровых дел с «этажиками». Не так уж и много — легко вмещается в несколько байт данных. Поэтому наилегчайшим способом для управления является прямая передача значений в регистры GPIO через DMA. Сейчас попытаюсь объяснить что же это такие за звери. В нашем микроконтроллере есть служебная часть памяти, где хранятся всякое. Например, состояние ножек. (Обычно процессор имеет почти мгновенный доступ к регистрам, и они находятся вблизи ядра — это так, к сведению.) А DMA – контроллер прямой передачи данных из одного адреса памяти в другой без участия процессора. Так мы можем настроить DMA по таймеру, чтобы передача производилась через определенный промежуток времени, указать регистры GPIO в качестве «цели» и спокойно попивать чаек. Потом нас оповестят, когда половина данных передастся, чтобы можно было подсунуть новые.
Но почему бы не усложнить модель? И так, сейчас мы уже смогли бы видеть, как наши светодиоды светятся красным и синим. А если делать паузы между включениями, то и что-то промежуточное.  Но чтобы получить нормальный градиент, частоту передачи стоило бы немного подкрутить. Например, мы хотим 100фпс для изменения цвета в 36 оттенков. Если 100фпс умножить на количество цветов (2), еще на 36 оттенков и, в конечном итоге, на 7 «этажиков» нашего куба (ведь одновременно горит лишь один), то получается 50400 — именно такая частота смены изображения должна быть. По мне так это какое-то большое число. Особенно, когда можно сделать экономичнее.
Но чтобы получить нормальный градиент, частоту передачи стоило бы немного подкрутить. Например, мы хотим 100фпс для изменения цвета в 36 оттенков. Если 100фпс умножить на количество цветов (2), еще на 36 оттенков и, в конечном итоге, на 7 «этажиков» нашего куба (ведь одновременно горит лишь один), то получается 50400 — именно такая частота смены изображения должна быть. По мне так это какое-то большое число. Особенно, когда можно сделать экономичнее.
Сейчас мы передаем информацию о цвете фреймами одинакового размера, но с помощью магии таймеров возможно это изменить. В частности, можно разделить каждый фрейм на 2 более мелких с разной шириной. И у нас будет, например, 1/3 первого фрейма для красного цвета и 2/3 для синего, а во втором наоборот. И благодаря этому всего из 2 фреймов можно сделать по 3 уровня яркости, без учета нулевого состояния. Нужно 2/3 яркости красного — включаем красный во втором фрейме, 3/3 — включаем оба.
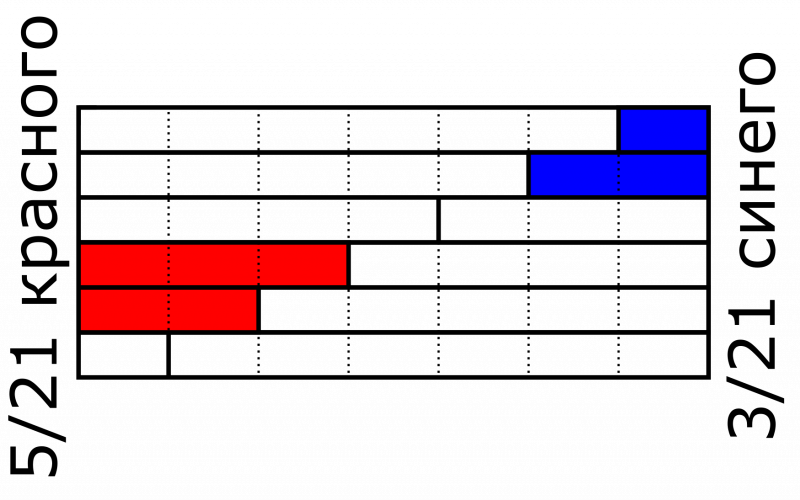
И для реализации этого надо добавить нашему таймеру пару ШИМ-каналов, да прикрутить к нам DMA.
Принцип:
Сначала обновляется глобальный счетчик таймера и мы триггерим DMA, загружающий данные в регистр сравнения ШИМ, то есть, фактически, размер нашего маленького фреймика в фрейме.
Потом триггерится заранее настроенный канал ШИМ для передачи данных, например, красного цвета. Позиция его в фрейме никогда не меняется.
И конце концов триггерится заданный в первом шаге канал, загружая данные синего цвета.

И главное, что мы упрощаем программную обработку и требование памяти в сравнении с фреймами одинакового размера.
Микрофон и его друзья.
В устройстве я использую аналоговый MEMS микрофон с верхним расположением звукового окна. Сам корпус для защиты от пыли я прикрыл поролоном, в который любезно были укутаны заказанные микроконтроллеры.

Но одного микрофона недостаточно для записи — сигнал необходимо еще и усилить. Тут я не стал мелочиться и задействовал аж 4 операционных усилителя (ОУ). Сначала сигнал через разделительный конденсатор проходит U14C, который усиливает на 10 и немного фильтрует. Потом через U14B, где цифровым потенциометром задается коэффициент усиления. И конце через полноценный фильтр нижних частот на U14D. И оставшийся ОУ формирует виртуальную землю. Весь каскад усиления дает частоту среза около 10кГц и, честно говоря, схема имеет все возможности для усиления в тысячи раз. Правда, самый большой коэффициент усиления, который используется мной — 70.
А теперь о грустном. Когда я планировал устройство, то от микрофона требовалось только одно — возможность давать адекватные данные для обработки нейросетью. Но, как говорится, аппетит приходит во время еды. И для использования для записи голоса и т. п. высота шумовой полки была ну такой себе. Мы же не хотим, чтобы наши личные агенты ФСБ/КГБ/ЦРУ страдали, так ведь?
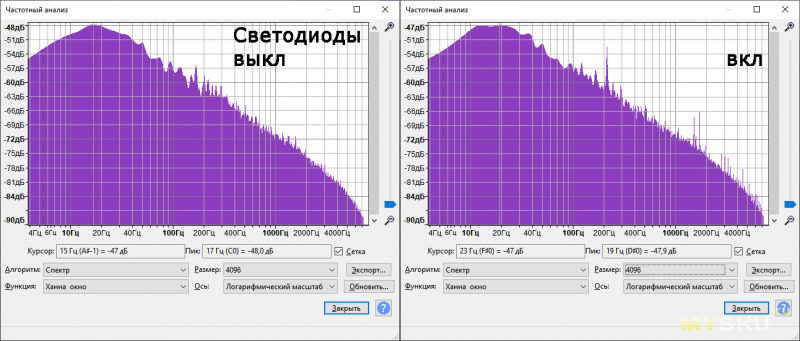
Тут сразу напрашивается одна не очень интересная история. Однажды я немного переписал прошивку, в результате чего получил мечту эпилептика на светодиодах. Но что более интересно, если приблизиться к девайсу поближе, был слышен выраженный высокочастотный шум. Это далеко не первый раз, когда я сталкиваюсь с таким, поэтому виновники были сразу найдены. Ими оказались керамические конденсаторы с выхода повышающего преобразователя для светодиодов. Неприятно, но будем исправлять! Сначала добавил к ним в параллель тантал на 47u. Шум стал значительно меньше. А затем что-то Остапа понесло и он запаял полимер на 150u. Стало еще чуть лучше.
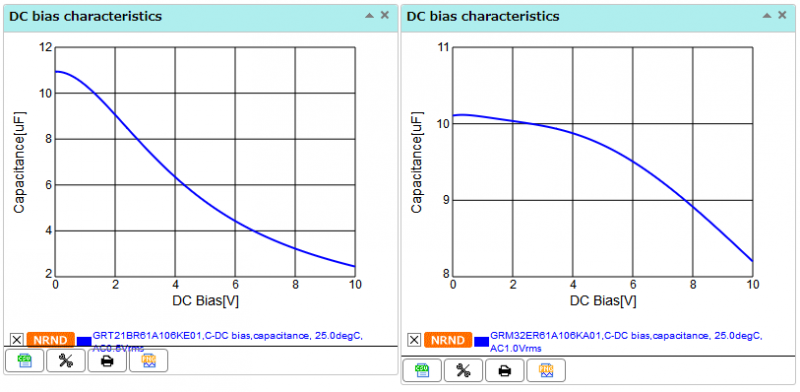 Конечно, правило условно и стоит прежде всего смотреть в документацию производителя (в которой этого обычно нет), но примерное представление можно получить и по данным о таких же конденсаторах, например, на сайте Murata.
Конечно, правило условно и стоит прежде всего смотреть в документацию производителя (в которой этого обычно нет), но примерное представление можно получить и по данным о таких же конденсаторах, например, на сайте Murata.Правда, мне быстро наскучило искать реальную причину, почему на микрофон приходит шум (ставлю на дроссель) — лучше уж сделать костыль. Раз есть целый микроконтроллер, то мы можем применить цифровой IIR-фильтр низких частот. И нет, вариант с выводом частоты работы светодиодной системы за грань слышимости не рассматривается, ибо просто не работает — я изменил с 12к до 20к и толком ничего не поменялось, кроме тональности шума (она стала противнее). Да и по графику спектра видно, что шум уходит на частоты пониже.
Но не этой проблемой едины. Вот вы знаете о такой проблеме операционных усилителей, как Phase-Reversal? Бывает, когда на входе операционника напряжение превышает лимит, то на выходе фаза сигнала меняется на противоположную…
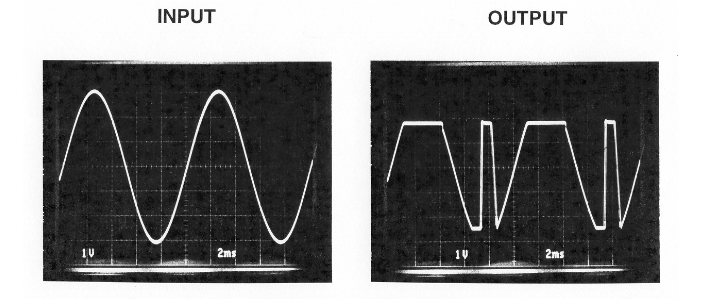
Можно почитать здесь.
Есть несколько путей решения такого. Во-первых, можно просто не превышать параметр common-mode input voltage, что мне не помогло. Во-вторых, можно использовать более толерантные к таким проблемам ОУ. И, в-третьих, можно просто вылавливать проблему с помощью микроконтроллера и что-нибудь делать. Я частично воспользовался третьим вариантом — настроил watchdog в АЦП, который предупреждает, если напряжение выше или ниже лимита. И в случае этого варианта, просто уменьшаю громкость усилителя микрофона, убирая основную причину явления.
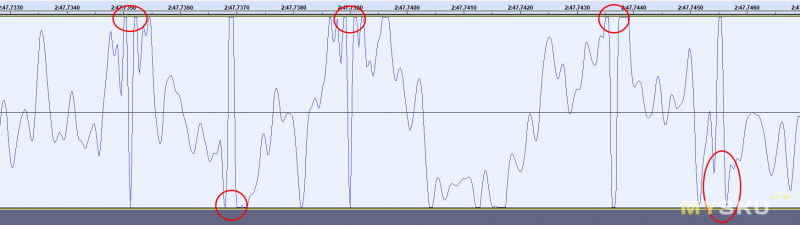
Можете глянуть на «красоту» проблемы. Только учтите, что Windows настолько хитрая система, что если выставить громкость микрофона в 100%, то вместо реальных 100% она сделает усиление где-то на 30Дб. А реальная единица громкости находится в районе 50-55%. И на скрине громкость выставлена неправильно, поэтому клиппинг тут не равен клиппингу в устройстве.
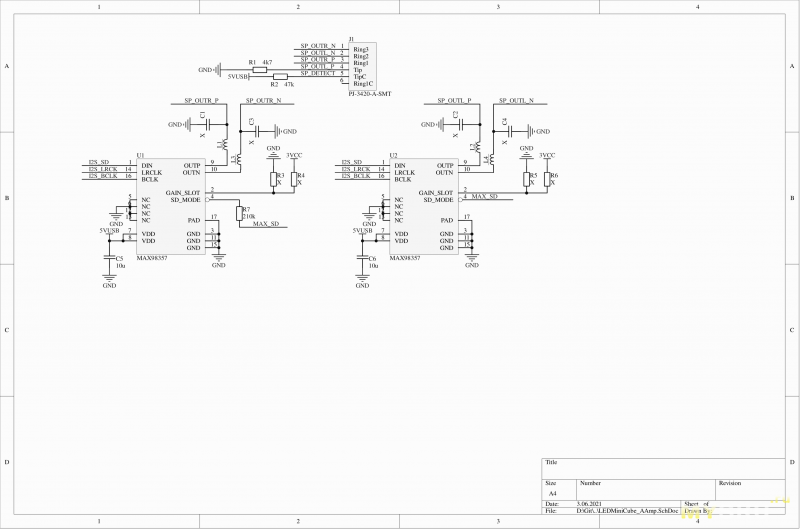
«Усилитель для динамической головки громкоговорителя».
Что-то в последнее время некоторые способы передачи аудио сигнала становятся все более архаичными. Вот мы берем цифровые данные и нагло отправляем в ЦАП, делающий аналог. А потом еще более нагло берем этот аналог и пихаем в усилитель класса D, который делает из аналога цифру и затем из цифры аналог. Как-то очень это странно выглядит… Поэтому лично я буду сразу пользоваться всеми благами прогресса и отправлять по I2S протоколу цифровое аудио сразу в усилитель, коим выступит MAX98357A. На выходе можно получить до ~2Вт на канал. В теории, ибо все же печатная плата к этому не располагает. Да и в целях экономии места в качестве выходного разъема использовал обычный 4х-пиновй 3.5, который мало того, что требует самодельного переходника для колонок, ибо подключение-то балансное, так и может всего 0.5А на контакт.
По поводу работы микросхемы претензий нет — для бумбокса самое то. Только лучше бы кабелек не абы какой к колонкам, дабы помех не было. Кстати, подключал свои Sennheiser HD598 – звук шумноватый; без живости, присущей сакуре, которая цветет на склонах самых великих гор. В общем, если бы не шум, то даже можно раз в год для разнообразия послушать в наушниках.
USB подключение
В наличии 2 USB входа, переключаемые через аналоговый мультиплексор. И небольшая заготовка под OTG, которая пока не используется. Но тут хотелось бы поговорить о софтовой части. Во-первых, как вообще определить, что мы успешно подключены? Использовать SOF-пакеты! Дело в том, что хост посылает каждые 1мс (для Full Speed) или 125мкс (для High Speed) Start Of Frame пакеты, по которым легко можно отследить коннект.
Но это легко, а вот как синхронизировать аудио между USB и усилителем, если в устройстве отсутствуют необходимые кварцевые резонаторы/генераторы для аудио-частот? Наши STM в своей библиотечке предлагаю или заполнять пустыми семплами, если приходит меньше, чем надо, или наоборот — резать приходящее. Реализация, если честно, так себе. Но есть решение! С одной стороны хорошее, а с другой… Аудиофилы будут снова в бешенстве!
И так, у нас в микроконтроллере стоит отдельный PLL (грубо говоря, генератор частоты) для аудио. И мы можем скидывать данные с USB в буффер и, если надо, поддавать газку — или наоборот. Подумаешь, частота аудио будет 44100+-140Гц — всего-то ошибка 0.3%.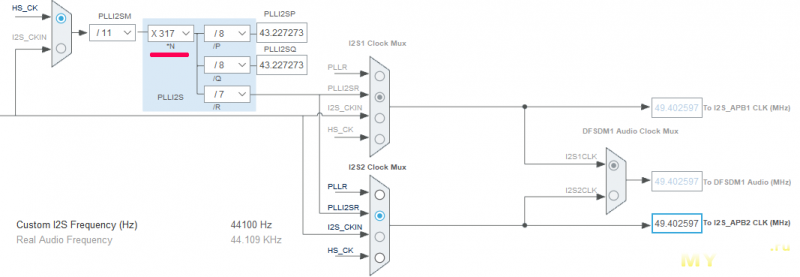 Конечно, в даташите черным по белому написано, что нельзя менять множители PLL на лету. Но кому не нравится, может останавливать тактирование и менять — я же слишком непокорен, чтобы слушать всякие там справочники. Тем более, эмпирические органы чувств не заметили проблем (а мерить неэмпирическими мы не будем).
Конечно, в даташите черным по белому написано, что нельзя менять множители PLL на лету. Но кому не нравится, может останавливать тактирование и менять — я же слишком непокорен, чтобы слушать всякие там справочники. Тем более, эмпирические органы чувств не заметили проблем (а мерить неэмпирическими мы не будем).
Вообще, самое страшное в программной реализации USB – это дескрипторы, с помощью которых хост понимает, что за ерунда подключена. Когда с первой попытки написать свой дескриптор для микрофон+аудио+ком порт я потерпел неудачу, пришлось подсматривать в генератор кода для Microchip микроконтроллеров, где такое добро бесплатно валяется. «Написали» дескрипторы, перенастроили конечные точки, скопировали куски кода из различных реализаций в интернете и получили рабочий интерфейс. Легко (ага!).
Сенсорные кнопки, «погодная станция»
3 сенсорные кнопки на TTP224B – больше сказать нечего. Работают и ладно.
А вот датчик температуры и влажности, коим является HDC1080, пришлось немного «отделить» от основной платы, чтобы лишнее тепло не сильно искажало значения. И при нормальном использовании разница между моим эталонным измерителем на BME680 составляет всего где-то пол градуса.
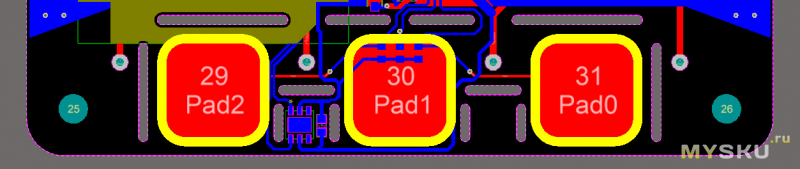
Нейросеть
Сразу стоит отметить, что это моя первая в жизни нейронная сеть, поэтому описывать принципы ее работы я не буду, да и не способен.

Краткий пересказ действа: записываем кучу слов -> делим каждый звуковой файл на куски, над которыми выполняется преобразование Фурье и генерация MFCC (Мел-кепстральных коэффициентов) -> полученные коэффициенты для каждого файла склеиваем в матрицу -> обучаем по ней свёрточную нейросеть -> получаем файл с нейросетью, на вход которой надо подавать матрицу MFCC коэффициентов, а на выходе — массив вероятностей. Потом файл с нейросетью отправляем прямой дорогой к генератору кода для микроконтроллера и получаем ее реализацию на C. А далее — рутина.
Теперь чуть углубимся в философию реализации. Нам надо, чтобы голосовые команды работали всегда, поэтому микроконтроллер должен успевать обрабатывать нейросеть множество раз в секунду. И так, частота записи микрофона — 16кГц. Мы будем записанные данные делить на части в 1024 семпла, чтобы потом провести FFT (быстрое преобразование Фурье) и из него генерировать MFCC. Дальше надо определить, сколько таких отрезков по 1024 семпла мы будем отправлять в нейросеть. И это важная часть, ибо чем их больше, тем дольше процесс выполнения. Я решил брать по 15 частей в 1024 семпла. Это 0.96с звука, что как раз вмещает одно слово. И, как уже можно догадаться, наша нейросеть будет ловить отдельные слова, выполняясь 15.6 раз в секунду, чтобы не упустить ничего.
Что-то похожее, только в числовом виде, попадает на вход нейросети
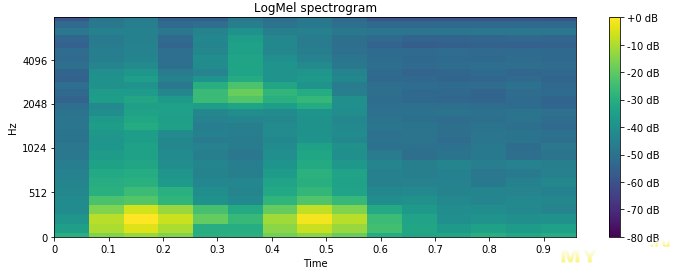
Но вернемся назад — к обучению. В этом всем процессе 90% успеха заключается в качестве базы голосовых команд. На каждую отдельную команду надо многие сотни примеров ее произношения. И с этим у меня возникли проблемы. Надо понимать, что в открытых базах нет необходимых слов, поэтому необходимо записывать самому. А если записывать самому, то точность очень пострадает, да и будет работать только на себя любимого. Вот вам, кстати, интересный пример, который заставляет задуматься — слово, сказанное в спокойном состоянии, будет отличаться от сказанного во фразе, ибо в первом случае у нас в легких куча воздуха, связки спокойны и т. п. Поэтому если записывать примеры, повторяя одно и то же много раз (как это делал я), то они не будут равны тем, что используются в контексте. Да и абы какое слово нельзя брать для команд — чем произношение проще, тем вероятнее ошибка в определении нейросетью. Например, я выбрал в качестве старт-слова «Ледокол» — оно укладывается в 0.96 секунды и довольно сложно в произношении. Поэтому ошибок в его определении почти нет. Да и сам девайс тоже назван «Ледокол» (вовремя, да?), так что можете официально начинать шутить о произношении в «латинском» варианте (LED Ok All).
Теперь прыгаем уже вперед — на реализацию в микроконтроллере. Самый сложный момент, поджидающий на этом шагу — необходимость повторения всей той обработки, которую мы делали для тренировки нейросети. Удивительно, но алгоритмов генерации MFCC множество. И, что самое смешное, для одинаковых данных получается различный результат. Благо, есть официальный пример от STM, где реализация точь-в-точь, как в пайтоновской библиотеке librosa. А реализацию FFT можно получить из библиотек от ARM. Хоть тут без велосипедов.
И теперь, когда все подготовлено, можно думать о логике команд. Во-первых, надо понимать, что у нейросети очень много ложных срабатываний, поэтому чем больше слов в самой команде, тем лучше. Я остановился на 4 словах. Сначала идет вступительная часть из 2 отдельных слов «Ледокол» и «Пожалуйста» (даже железки требуют уважения), а уже потом то, что характеризует команду. Пример: «Ледокол — Пожалуйста — Произнеси — Температуру», «Ледокол — Пожалуйста — Выключи — Микрофон» и т.д. Также применяются некоторые меры для подавления ошибок:
- Блокирование на время нейросети, когда успешно опознано слово (например, в слове «Ледокол» содержатся слова «лед» и «кол», на которые, в случае чего, могло бы реагировать)
- Очистка результата опознания, если прошло больше 5-6с после старт-слова
- Неучет распознания, если слова не на своих местах (например, в «Ледокол — Включи — Пожалуйста» последние 2 слова учитываться не будут).
Все это позволяет практически исключить случайные срабатывания — в конечном варианте такое случается лишь раз за 5-10 часов разговора.
В целом, вещь очень занятная. Я уже и успел забыть, как управлять Ледоколом кнопками. Огорчает лишь необходимость ставить паузы между словами, чтобы сильно уменьшить промахи, но думаю, это из-за качества базы обучения. На этот факт еще указывает результат усложнения нейросети в 2 раза (по времени выполнения микроконтроллером) — точность не повышалась.
Пример работы голосовых команд
Заключение
Это получился отличный конструктор для себя любимого. Но если вдруг к вам придет глупая идея повторить такое, то не советую — ни документации, ни внятной инструкции я не предоставляю. Но как идею, можете взять на вооружение.
И в конце хочется выразить благодарность своему другу — Ване Ф. Без его глупых советов не в тему мне бы не хватило силы воли закончить «Ледокол».
Github проекта — https://github.com/Diject/Ledokall
- Замена и допилинг щёточного узла эл. двигателя шуруповёрта
- 3D печатные держатели для аккумуляторов и батарей - питание без единой капли припоя
- Часы "Восток" калибр 2605 (почти) 17 камней. Смех сквозь слёзы.
- Делаем вечную лампочку
- Усилитель для фотодиода с расширенным частотным диапазоном.
- Фильтр-корректор для сабвуфера в акустическом оформлении "закрытый ящик".
- Ремонт бензопилы Oleo Mak. заводится, но без подсоса глохнет. очень простой ремонт
- Эксперимент: можно ли "прикурить" авто дешевыми аккумуляторами для фонариков?
- Фотоаппарат Киев-17. Быстрый ремонт затвора или повесть о непритязательном бастарде NIKON_а.
- Сабвуфер 100 литров в акустическом оформлении "закрытый ящик" на базе динамика 100ГДН-3.


Вам также может понравиться

FM-радиоточка "Мэта 212". Как это устроено

Колодка на макита-подобные аккумуляторы
